

Structured Design (SD).ppt
- Ziele des Designs
- Begriffe
- Modularisierung
- Structure Charts
- Die Modulspezifikation
- Die Qualitätsbewertung eines Designs
- Wie kommt man von der Analyse zum Design?
- Wie geht`s weiter?
Ziele des Designs
Bei allen besprochenen Analysemethoden ist die Erstellung eines (möglichst) von Implementationsdetails freien Modells das Ziel. Jetzt, bei der Konstruktion des Sytems, kommen Implementationsdetails zum tragen. Die Prozessorgrenzen werden festgelegt und es findet die Festlegung der Implementierungstechnologie statt.
Dabei werde die folgenden Aspekte behandelt:
- die Machbarkeit wird untersucht,
- die konkreten Typen von HW- und SW-Umgebung werden festgelegt,
- die benötigte Kapazität wird ermittelt, und
- die Kosten für Beschaffung und Betrieb werden ermittelt.
Das Analysemodell (SA + RT + SM) mit seinen meist parallelen Prozessen muß also in ein Designmodell ( SD) überführt werden, das den Architekturen der vorhanden HW-/SW-Basis folgt. Dabei muß die Abbildung vom Analysemodell zum Designmodell (und umgekehrt) jederzeit nachvollziehbar sein.
Begriffe
Bevor wir uns SD zuwenden müssen wir den Begriff Modul definieren und die andere Verwendung des Begriffs Funktion erläutern.
Ein Modul ist eine Sammlung von Programmanweisungen bzw. elementaren Funktionen. Er hat einen
- Namen, aus dem hervorgeht was er tut, er ist
- aufrufbar, kann
- Daten übernehmen,
- Daten zurückgeben.
Das ist die äußere Sicht auf einen Modul. Die innere Sicht, die
- interne Funktionalität und
- interne Daten
hä er verborgen (Information-Hiding).
Ein Modul besteht aus ein oder mehreren Funktionen.
Eine Funktion ist die kleinste Gruppe von Anweisungen, die sich als Einheit ansprechen läßt.
Modularisierung
Sinn der Modularisierung ist die Gliederung eines Systems in überschaubare und pflegbare Teile. Außerdem soll Coderedundanz vermieden und Mehrfachverwendbarkeit von Modulen (besser noch von einer Reihe zusammenarbeitender Module) erreicht werden.
Structure Charts
Ein SC zeigt die äußere Sicht der Module und die Beziehungen der Module untereinander. Die innere Sicht der Module, wann und wie oft ein Modul von einem anderen gerufen wird oder in welcher Reihenfolge ein Modul andere ruft wird nicht dargestellt.
Die folgende Tabelle zeigt eine Auswahl der am häufigsten zur Darstellung verwendeten Symbole. Eine vollständige Beschreibung befindet sich in /Yourdon, Constantine/.
| Symbol | Benennung | Bedeutung / Bemerkungen |
|---|---|---|
| |
Modul | Module müssen innerhalb des Models in
Modulbeschreibungen weiter spezifiziert werden, um die innere Sicht"
für die Implementierung festzulegen. Als Makro gestrichelt. |
| |
Bibliotheks- Modul |
Module aus der Entwicklungsumgebung oder aus dem
laufenden oder fremden Projekten, die allgemein zugänglich in Bibliotheken
abgelegt sind. Die Modulbeschreibung ist an anderer Stelle erstellt. Als Makro gestrichelt. |
| Daten | Modul, der ausschließlich Daten enthält. | |
| Modulauruf call asyn. call Hut-Symbol |
Die Steuerung geht vom rufenden an den gerufenen Modul. Rufender und gerufener Modul arbeiten parallel weiter. Inline Code |
|
 |
Übergabeparameter | Datenelement, Übergaberichtung Steuerelement, Übergaberichtung Hybridelement, Übergaberichtung auch Referenz in Parametertabelle möglich |
| Loop | Kennzeichnet wiederholte Aufrufe | |
| Decision | Nachfolgende Module werden bedingt und alternativ aufgerufen. |
Symbole in Structure Charts
Bei der Vergabe der Namen für Module und Daten ist darauf zu achten, dass die Bedeutung (Semantik) für den Leser sofort verständlich ist. Es gelten auch hier die Empfehlungen der SA. Bei der Vergabe von Moduleamen ist auch darauf zu achten, dass ein Modul auch die Leistung aller von ihm gerufenen Module enthä, die also im Namen ebenfalls berücksichtigt werden müssen. Die Namen von Daten müssen im Datenkatalog definiert sein.
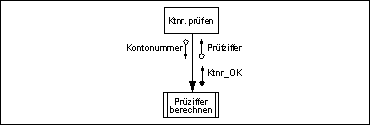
Beispiel für Modulaufruf
Module sollten im Structure Chart so angeordnet werden, dass
- Eingabe-Module (Daten nach oben) soweit wie möglich links,
- Ausgabe-Module (Daten nach unten) soweit wie möglich rechts,
- Verarbeitung in der Mitte und
- Quellen und Senken (Lesen und Ausgaben von Daten) als Blätter dargestellt werden.
Ein Beispiel für ein einfaches Structure Chart ist /Raasch/ entnommen.
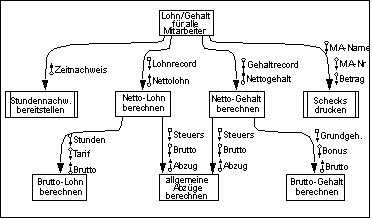
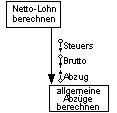
Beispiel eines einfachen Structure Chart
Die Modulspezifikation
Nach der Definition der äußeren Sicht muß die innere Sicht eines Moduls spezifiziert werden. Die Spezifikation erfolgt in der Regel in Modulköpfen und Pseudocode oder formalen und/oder grafischen Spezifikationen (siehe Kontrollstrukturen und Entscheidungstabellen).
Der Modulkopf enthä im allgemeinen den Namen, eine kurze Funktionsbeschreibung, eine Spezifikation der benutzten Parameter. Er wird in der Codierphase um Versions- und Änderungsdaten ergänzt.
Wenn eine klare Zuordnung zwischen den Mini-Spezifikationen der SA und den Module der SD besteht, dann können diese Spezifikationen kopiert werde. Ggf. reicht auch der Verweis in die Mini-Spezifikationen.
Die Qualitätsbewertung eines Designs
Die Zerlegung eines Systems in Module garantiert allein noch keine hohe Änderbarkeit und Anpaßbarkeit. Man muß schon einige Regeln beachten um die folgenden Qualitätskriterien eines Designs zu erfüllen.
- Überschaubarkeit
Module sollten im quantitative (Anzahl Statements) und qualitativen (Anzahl von Algorithmen oder Daten) Sinne eine überschaubare Größe besitzen (2 Seiten sollten reichen). - Geringe Modulkopplung (Coupling)
Die Kopplung definiert den Grad der Abhängigkeit von Module. Je loser die Kopplung zwischen Module ist, um so weniger beeinflussen sich die Module gegenseitig. Damit wird erreicht, dass ein Modul ohne Auswirkung auf das übrige System gegen einen anderen Modul mit gleicher Schnittstelle austauschbar ist und dass ein Modul keine internen Details anderer Module kennen muß. - Hohe Modulbindung (Cohesion)
Die Bindung definiert den Grad der Zusammengehörigkeit der Funktionen eines Moduls. Je größer die innere Bindung eines Moduls ist um so mehr kann man davon ausgehen, dass er genau eine Aufgabe vollständig löst.
Kopplung und Bindung stehen in Beziehung zueinander. Module hoher Bindung besitzen lose Kopplung bzw. lose Kopplung ist nur bei starker Bindung möglich.
Die Kopplung wird unterschieden in
- drei Arten der normalen Kopplung, die
- globale Kopplung und die
- Inhaltskopplung.
Normale Kopplung zwischen einem Modul M1 und M2 besteht, wenn
- M1 den Modul M2 aufruft,
- M2 nach Abschluß seiner Aktionen die Kontrolle an M1 zurückgibt und
- die Kommunikation zwischen M1 und M2 über explizit festgelegte Aufrufparameter stattfindet.
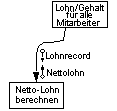
| best | Die normale Kopplungsart Datenkopplung (Data Coupling), bei der die Übergabeparameter elementare Strukturen sind (Felder oder homogene Tabellen).
|
 |
|---|---|---|
Die normale Kopplungsart Datenstrukturkopplung (Stamp Coupling), bei der komplexere Datenstrukturen übergeben werden.
|
 |
|
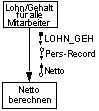
Die normale Kopplungsart Kontrollkopplung (Control Coupling), bei der Parameter übergeben werden, die den Ablauf des anderen Moduls beeinflussen. D.h. die Parameter haben den Charakter von Schaltern, mit denen Einfluß auf den anderen Modul ausgeübt wird.
|
 |
|
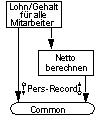
Die globale Kopplung (Global Coupling oder Common Coupling), bei der Module über einen gemeinsamen Speicherbereich kommunizieren. Ein Fehler eines Moduls kann sich über den Speicher auf die anderen Module auswirken.
|
 |
|
| worst | Die Inhaltskopplung (Content Coupling), bei der ein Modul das Innere eines anderen adressiert (z.B. in Assembler möglich). Diese Kopplungsart muß verboten sein. | keine Darstellung vorgesehen. |
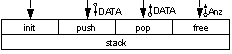
Modulkopplung
Die Bindung wird unterschieden in
- drei normale Bindungsarten,
- prozedurale Bindung,
- zeitliche Bindung,
- logische Bindung und
- zufällige Bindung.
Von normaler Bindung spricht man, wenn der Modul nur inhaltlich eng zusammengehörige Funktionen erfaßt die auf gemeinsamen Daten operieren, die entweder als Parameter übergeben werden oder lokal definiert sind.
| best | Die normale Bindungsart Funktionale Bindung (Functional Cohesion) liegt vor, wenn die Gesamtheit der Funktionen eines Moduls einer einzigen, geschlossenen Aufgabe dient. | 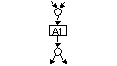 |
|---|---|---|
| Die normale Bindungsart Sequentielle Bindung (Sequential Cohesion) liegt vor, wenn seine Funktionen eine zusammenhängende Folge von Aktivitäten darstellt, wobei die Ausgabedaten einer Funktion die Eingabedaten der nächsten Funktion sind. | 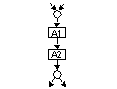 |
|
Die normale Bindungsart Kommukative Bindung
(Communicatial Cohesion) liegt vor, wenn die Funktionen eines Moduls dieselben
Eingabe- oder Ausgabedaten nutzen.
|
 |
|
| Die Prozedurale Bindung (Procedural Cohesion) liegt vor, wenn völlig unabhängige Funktionen lediglich die Gemeinsamkeit haben, dass zur selben Zeit oder zu einem bestimmten Zeitpunkt in einer festen Reihenfolge ablaufen (z.B. Initialisierung). | ||
| Die Zeitliche Bindung (Temporal Cohesion) liegt vor, wenn der Modul aus völlig unabhängigen Funktionen besteht, die nur die Gemeinsamkeit haben, dass sie nacheinander ablaufen. | ||
Die Logische Bindung (Logical Cohesion) liegt
vor, wenn die Funktionen des Moduls programmstrukturell miteinander verflochten
sind und ihre Ausführung beim Aufruf über ein Flag gesteuert wird.
|
||
| worst | Die Zufällige Bindung (Coincidental Cohesion) liegt vor, wenn die Funktionen des Moduls keine sinnvolle Beziehung haben. Z.B. willkürliche Aufteilung aufgrund von Platzproblemen. |
Bindungen
Neben den Kriterien Kopplung und Bindung gibt es noch eine Reihe weiterer beachtenswerter Eigenschaften, die in ihrer Summe erst ein gutes Design ausmachen.
Faktorisierung und Software-Architektur
Unter Faktorisierung versteht man die logische Zerteilung eines Modells nach den Kriterien Kopplung und Bindung. Das Ergebnis wird ein System mit minimaler Coderedundanz sein. Sollten Module zu klein werden oder sollten Performanceprobleme auftreten, so können Module als in-line-Code verwendet werden oder die Faktorisierung wird rückgängig gemacht.
Ferner ist auch darauf zu achten, dass eine Funktion vollständig in einem Architekturblock einer Software-Architektur angesiedelt ist. Bei der Schichtenbildung ist dafür zu sorgen, dass die eigentlichen Verarbeitungsfunktionen nur noch mit Daten arbeiten bei denen keine physikalischen Aspekte zu berücksichtigen sind.
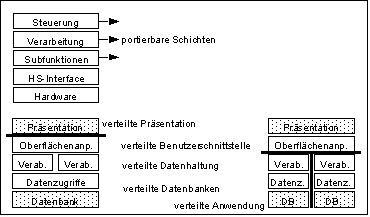
Beispiel für Architekturen
Decision Split
Eine Entscheidung hat einen Erkennungsteil (Bedingung) und einen Ausführungsteil (Aktionen). Beim Dicision Split werden diese beiden Teile auf verschiedene Module verteilt.
Diese Dicision Splits sollten möglichst vermieden werden. Eine Auslagerung der der Alternative in einen jeweils direkt aufgerufenen Modul ist jedoch vertretbar.
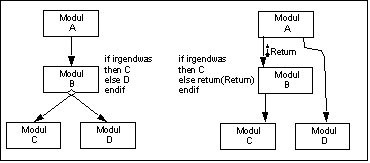
Beispiel für Decision Splits
Fehlerbehandlung und Prüfungen
Die Structured Analysis betrachtet keine Fehlerbehandlung. Jetzt müssen die Fehlerreaktionen einschließlich des Administrationsringes (Prüfarbeit) festgelegt werden. Hierbei sollten folgende Grundsätze beachtet werden:
- vollständige Fallunterscheidungen programmieren,
- Anstoß einer Meldungsausgabe möglichst durch den fehlererkennenden Modul,
- Ausgabe von Fehlermeldungen über einen Meldungsmodul
- mit zentraler Haltung der Fehlermeldungen, möglichst in Datei und
- festlegen, ob Prüfroutinen Meldung und/oder Returncode ausgeben.
Prüfungen von Daten müssen nach Übernahme in das System so früh wie möglich durchgeführt werden. Dabei ist die Reihenfolge:
- Zeichenprüfung,
- Feldprüfung,
- Prüfung von Kombination von Feldern und
- Plausibilitätsprüfungen gegen Datenbestände
bewährt. Module sollten darüber hinaus noch Eingabeparameter gegen die Bedingungen prüfen, die zu einem Programmabbruch führen könnten.
Nutzung von Static Variablen
Static Variablen dürfen nur sehr bewußt eingesetzt werden, denn dieses interne Gedächtnis kann dazu führen, dass ein Modul sein Verhalten von einem Aufruf zum nächsten ändern kann.
Initialisierung, Belegung, Freigabe und Terminierung
Initialisierungen, speziell von Zählern und Schleifenvariablen, sollten möglichst erst vor der tatsächlichen Nutzung stattfinden, da sonst Code schwerer verständlich ist (wo ist der Initialisierungsmodul ?). Die Module werden dann auch ohne Initialisierungsmodul lebensfähig. Initialisierung sollte so spät wie möglich und Terminierung so früh wie möglich stattfinden (besonders bei der Belegung von Betriebsmitteln). Auch sollte nach schweren Programmfehlern eine ordnungsgemäße Terminierung und Freigabe aller Betriebsmittel sichergestellt sein (zum Glück leisten das heute die meisten Betriebssysteme).
Aspekte der Wiederverwendbarkeit
Ein wiederverwendbarer Modul zeichnet sich dadurch aus, dass er möglichst keinen Restriktionen wie z.B. Dimensionierungsgrenzen unterliegt. Wirtschaftlich gangbar ist i.d.R. der Weg, dass Konstanten über Includes zur Copile-Zeit oder gar aus Parameterdateien heraus zur Laufzeit aktualisiert werden können (Konstanten mit Gültigkeitszeitraum). Die Erreichung von Wiederverwendbarkeit um jeden Preis, auch wenn sie gar nicht erforderlich ist, kostet uns unnötig Geld und hat zu unterbleiben.
Meßlatten
Höhe und Breite eines Systems und Fan-Out und Fan-In eines Moduls sind weitere Indikatoren für die Qualität eines Designs.
Tiefe ist die Anzahl der Ebenen der Aurufhierarchie, Breite ist die maximale Anzahl von Module in der Ebene. Ein System mit Höhe=Breite gilt als ausgewogen, ist aber natürlich auch von der Aufgabenstellung abhängig.
Fan-In gibt die Anzahl der Module an, die einen Modul rufen. Je größer ein Fan-In ist desto größer ist die Wiederverwenbarkeit eines Moduls. Die Erhöhung von Fan-In ist häufig durch weitere Faktorisierung möglich.
Fan-Out ist die Anzahl direkt gerufener Module eines betrachteten Moduls. Bei mehr als 7 +/- 2 leidet die Übersichtlichkeit des Structure Charts. Bei zu hohem Fan-Out schaltet man Manager-Module" zwischen.
Wie kommt man von der Analyse zum Design?
Um vom Analyseergebnis zum Design zu kommen, folgt man einfach der Strategie von /Yourdon, Constantine/, der
- transform analysis oder dem
- transform-centered design.
Die transform analysis oder transform-centered design besteht aus vier Schritten:
- der Beschreibung des Problems als Datenflußdiagramm,
- der Identifizierung der logischen und der physikalischen Datenelemente und ihrer Umsetzungen,
- der First-Level Faktorisierung und
- Faktorisierung der Zweige Daten physikalisch nach logisch", Verarbeitung" und Daten logich nach physikalisch".
Beschreibung des Problems als Datenflußdiagramm
Dieser Schritt ist anscheinend überflüssig, denn wird haben ja in der Strukturiereten Analyse DFDs erstellt. Übernehmen wird also einfach den Teil Kartenauskunft erteilen" aus unserem Vorverkaufssystem.
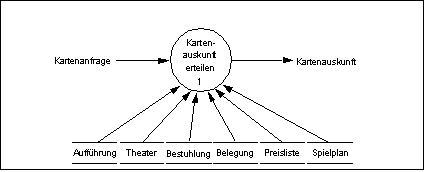
Datenflussdiagramm
Damit haben wir zwar formal den ersten Schritt erfüllt, werden aber bereits beim nächsten Schritt ins Stolpern kommen, denn wir haben hier nur logische Datenelemente. Wir müssen also das DFD physikalisieren, d.h. Festlegungen darüber treffen, wie die Ein- /Ausgabe stattzufinden hat. Dazu legen wir in jeden Datenfluß der eine Prozessorgrenze überschreitet einen Prozeß, der z.B. die Daten von Steuerzeichen befreit und prüft bzw. Steuerzeichen hinzufügt oder Protokolle abwickelt.
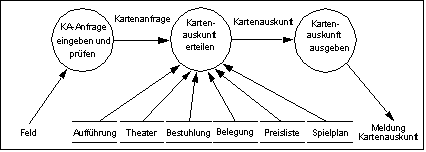
DFD physikalisiert
Identifizierung der logischen und der physikalischen Datenelemente
Jetzt können wir logische und physikalische Datenelemente identifizieren. Logisch sind Kartenabfrage und Kartenauskunft, physikalisch sind Aufforderung und Feld.
First-Level Faktorisierung
Hier wird zunächst ein Hauptmodul definiert, der durch den Aufruf untergeordneter Module die vollständige Arbeit abwickelt. Darunter werden - von links nach rechts- gruppiert:
- Die Module mit den aufsteigenden Daten, d.h. von der Physik zur Logik,
- die auf den logischen Daten arbeitenden zentralen VerarbeitungsModule und
- die Module mit den absteigenden Daten, d.h. von der Logik zur Physik.
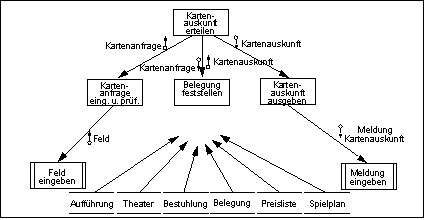
First Level Faktorisierung
Nach der First Level Faktorisierung werden die einzelnen Zweige unter Berücksichtigung der Regeln für Kopplung und Bindung weiter faktorisiert. Erfahrungsgemäß fällt diese Zerlegung leichter, wenn man sich an den Strukturen der Daten orientiert (siehe auch Jackson-Methode).
Ein mögliches Ergebnis zeigt die folgende Skizze. Der Dialog findet offensichtlich über ein Terminal im Blockmodus statt. Eine Prüfung der einzelnen Felder auf zulässige Werte und vollständige Eingaben findet nicht statt.
Die zulässigen Platzkategorien und die Fehlermeldungen sind in einer Datei hinterlegt (hoffentlich mit einem Standardeditor zu bearbeiten).
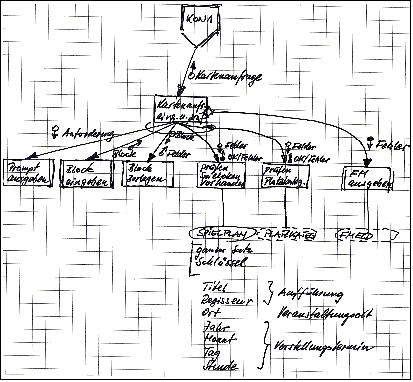
Beispiel für ein Structure Chart
Heute verwendete Oberflächen und Programmierumgebungen führen zu anderen Lösungen. Hier ist ein Beispiel für ein Formular, dass durch ACCESS erstellt wurde. Allein durch die Beschreibung der Datenformate werden entsprechende Prüfungen veranlaßt. Die Fehlermeldungen sind in diesem Fall allerdings recht pauschal.
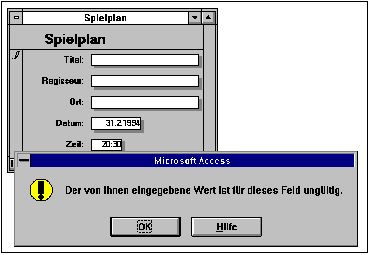
Beispiel für grafische Oberflächen
Durch diese neuen Programmierumgebungen ergibt sich bezüglich der Oberfläche folgende Architektur.
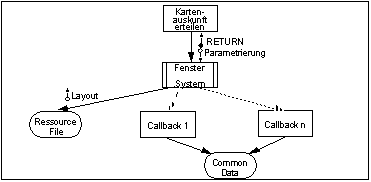
Structure Chart für grafische Oberflächen
Wie geht`s weiter?
Der weitere Weg liegt scheinbar klar vor Augen. Es folgt die Komponentenspezifikation und die Implementierung. Es wird fleißig getestet, im Code werden Änderungen durchgeführt.
Dabei wird dann leider meistens die Todsünde begangen, das Design und ggf. auch die Analyseergebnisse nicht mehr zu aktualisieren. Wenn dann das Projekt fertig ist, liegt ein Design vor (wenn überhaupt), das ein anderes System als das ausgelieferte System beschreibt. Es ist für künftige Erweiterungen oder den Einsatz in anderen Projekten kaum noch geeignet.
Gegen dieses Leiden helfen m.E. drei Pillen:
- Wir codieren nicht mehr selber, sondern suchen uns Werkzeuge, die aus dem Design den Code generieren. Dann können wir sicher sein, dass Designdokumentation und fertiges System übereinstimmen. Sollte ein generierter Code einmal wirklich nicht unseren Ansprüchen genügen, dann kann immer noch von Hand optimiert werden.
- Wir suchen uns ein Werkzeug, das aus unserem Code ein (Re-) Design macht.
- Wir üben uns in Selbstdisziplin und führen jede Änderung um System in unserem Design nach.
Die dritte Pille ist sicher die bitterste. Aber für eine von diesen müssen wir uns entscheiden, wenn wir nicht Systeme bauen wollen, bei denen jede Veränderung zur Krise führt.